Creating a New Column Type
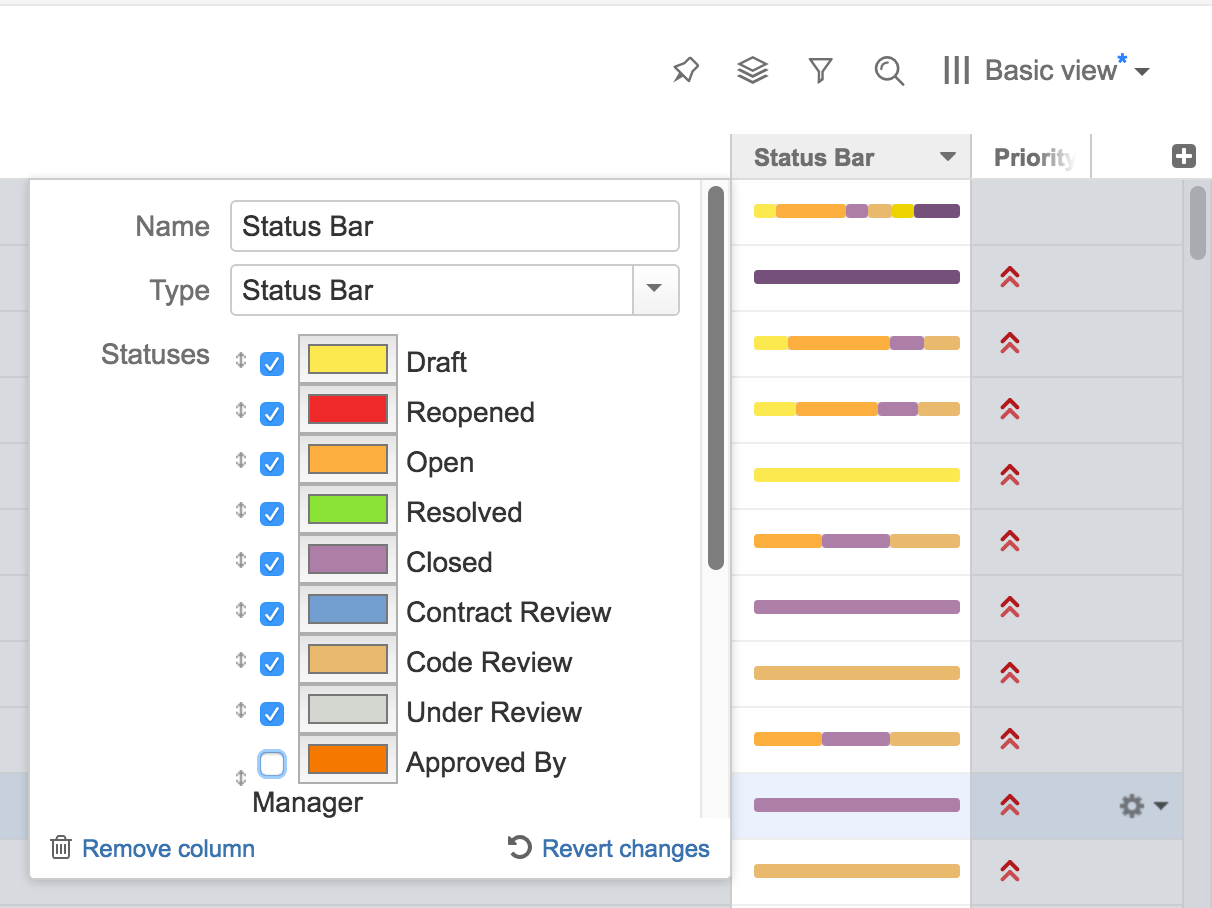
In this tutorial we will develop the Status Bar column type, which shows a progress-like bar filled with color stripes, each stripe's color representing a particular issue status, and each stripe's width being proportional to the number of issues having that status in the current issue's subtree.
You can download both the compiled plugin and its source code from API Usage Samples.
1. The Plan
A column type consists of several components. The client-side components are written in JavaScript and have two responsibilities:
- Rendering the cells in the Structure widget.
- Providing the column configuration UI.
The server-side components are written in Java and responsible for:
- Providing the attributes needed by the client-side part to render the cells.
- Exporting the column into printable HTML and Microsoft Excel formats.
For the Status Bar column we'll need to write code to cover all of the above responsibilities.
In general, however, only the client-side part is strictly necessary. If the attributes provided by Structure are enough for your column, you can skip the server-side attribute provider. You can also skip the components related to export, if this functionality is not critical. In that case, you can jump straight to the client-side part, consulting the other chapters as necessary. For the complete treatment, please continue reading from top to bottom.
2. The Attributes
Before we begin, let's decide which attributes we need to pass from the server side to render a status bar. Obviously, the status bar depends on the statuses of all the issues in the given issue's subtree. This suggests that we need to use an "aggregate" attribute, and because Structure does not provide such an aggregate out of the box, we'll need to write our own.
Secondly, the colors and the order of statuses in the status bar are only a presentational matter. If we had a map from status IDs to sub-issue counts in the given issue's subtree, we could count the total number of sub-issues, scale the colored stripes so that they'd fill the whole status bar, and render them in any given order.
Thirdly, the "Include itself" option is somewhat trickier. When it's on, the current issue's status is shown in its status bar, as if there is one more sub-issue. When it's off, the current issue is excluded, and the status bar shows only its sub-issues (on all levels). We could try to implement this on the server side as a separate aggregate, however, this approach has a couple of drawbacks:
- When the user toggles the checkbox, Structure will have to calculate a new aggregate and transfer the results. Because the aggregate values are cached on the server side, and issue data values are cached on the client side, on both sides we'll have increased memory consumption.
- Because of the way the aggregates are calculated and cached on the server side, the aggregate for the option turned off will be somewhat more difficult to write, and use a more complex data structure.
So, we'll do things differently, and use a single, simpler, aggregate, calculating the data with the "Include itself" option turned on. If it's off, we'll adjust the data on the client side. To do that, we'll need another piece of data – the status ID for the current issue, but that can be provided by Structure itself, and the overhead of requiring it is less than that of a separate aggregate.
3. AttributeSpec for Status Bar
Once we understood which attributes will our JavaScript code need, we have to define or find the appropriate attribute specifications for it.
Our status bar is going to be a new attribute, so we need to create an AttributeSpec. The ID for this spec should be something unique to our add-on. And the format should be a generic JSON_OBJECT, because we're going to transfer a bunch of data back to the client rather than just a single value.
public static final AttributeSpec<Map<String, Integer>> STATUS_BAR
= new AttributeSpec("com.almworks.statusbar", ValueFormat.JSON_OBJECT);We don't need any parameters for this attribute specification – regardless of column configuration, we'll always load the same attribute.
The value will be the map from the Status ID to the number of cases that status is encountered in the sub-tree, including the parent issue.
As for the status ID of the current row, we'll use CoreAttributeSpecs.STATUS_ID.
4. Status Bar Attribute
Now that we know which attribute we need to implement, let's write a loader of that attribute. A loader is an instance of AttributeLoader that loads specific attributes for a specific request.
We need to start by looking for the most convenient base class for our loader. It seems that AbstractNaiveDistinctAggregateLoader is the best, because:
- It is already a loader for an aggregate,
- It addresses the problem of having multiple issues in the same sub-tree more than once – obviously, we don't want to count such issue's Status twice.
This basic class is "naive" because the way it implements the distinct counting is very basic – and potentially consuming a lot of memory. Structure has more advanced methods for calculating the distinct totals, but it's not a part of the API as of version 17.
As the loader does not have any other parameters, we'll only need a single instance, which we'll keep in a static final field.
private static final AttributeLoader<Map<String, Integer>> LOADER = new StatusBarLoader();Our loader will have a dependency on the CoreAttributeSpecs.STATUS attribute. Structure will guarantee that the dependency attributes are loaded before our loader is asked to do its calculation.
All multi-row attribute loaders (aggregates, propagates and scanning loaders) must not access items directly, but rather declare dependency on item-based or single row-based attributes. This is needed by the attributes subsystem to function efficiently, but also, it lets other developers extend the applicability of those dependency attributes to a new type of items. In that way your aggregate attribute will immediately work with the new item types, even though you didn't know about them at development time.
The calculation of the result is pretty straightforward. The base class, AbstractDistinctAggregateLoader, defines two methods for building recursive value: getRowValue() provides a single value for a single row and combine() accumulates the provided values.
- As a result for a single row, we create a map with just one record: the issue's status is mapped to 1. If status is missing (as would be the case for non-issues), we just return null.
- As a combination function we will implement map merge that combines counters.
- Finally, we return an immutable copy of the
resultmap.
StatusBarAggregate.java
private static class StatusBarLoader extends AbstractNaiveDistinctAggregateLoader<Map<String, Integer>> {
public StatusBarLoader() {
super(STATUS_BAR);
}
public Set<AttributeSpec<?>> getAttributeDependencies() {
return Collections.singleton(STATUS);
}
protected Map<String, Integer> getRowValue(RowAttributeContext context) {
Status value = context.getDependencyValue(STATUS);
return value == null ? null : Collections.singletonMap(value.getId(), 1);
}
protected Map<String, Integer> combine(Collection<Map<String, Integer>> values, AggregateAttributeContext context) {
HashMap<String, Integer> r = new HashMap<>();
for (Map<String, Integer> map : values) {
if (map != null) {
for (Map.Entry<String, Integer> e : map.entrySet()) {
Integer count = r.get(e.getKey());
if (count == null) {
count = 0;
}
r.put(e.getKey(), count + e.getValue());
}
}
}
return r;
}
}5. Attribute Provider
Attribute providers are registered as modules in the plugin descriptor, and their instances are created by the JIRA module system. If the attribute provider "recognizes" the attribute specification and can serve it, it must return a non-null AttributeLoader instance. Because our StatusBarLoader implementation is stateless and has no parameters, we can reuse the single static final instance, but a configurable data provider could create and return new loaders for each call. The returned loader will then be called once for each item needed to display the Structure grid (or its visible part).
StatusBarDataProvider.java
public class StatusBarAttributeProvider implements AttributeLoaderProvider {
private static final AttributeSpec<Map<String, Integer>> STATUS_BAR = new AttributeSpec("com.almworks.statusbar", ValueFormat.JSON_OBJECT);
private static final AttributeLoader<Map<String, Integer>> LOADER = new StatusBarLoader();
public AttributeLoader<?> createAttributeLoader(AttributeSpec<?> attributeSpec, @NotNull AttributeContext context)
throws StructureProviderException
{
if (STATUS_BAR.getId().equals(attributeSpec.getId())) {
return LOADER;
}
return null;
}
}
When the data provider is ready, we register it in the plugin descriptor.
atlassian-plugin.xml
<structure-attribute-loader-provider key="alp-sbcolumn" name="attribute-loader:Status Bar Column"
class="com.almworks.jira.structure.sbcolumn.StatusBarAttributeProvider"/>6. Client-Side Column
We now come to the most visible part of the column – the client-side JavaScript code, responsible for rendering the cells of the Structure grid and showing the column configuration UI. Having almost 400 lines of JavaScript, the code is too long to be reproduced in its entirety. We advise you to download the API examples source code from the API Usage Samples page and open sbcolumn.js from the status-bar-column sample plugin in your favorite editor.
First, we'll take a high-level overview of the API and look at a few common concepts – column specifications, column context, and the metadata. After that we'll discuss each of the API classes and their implementations.
6.1. API Overview
The whole API is accessible through the window.almworks.structure.api global object. There are a few utility functions and four main classes that the developer needs to extend (by using the api.subClass() function) in order to create a fully-functional column. These classes are linked together by the column specification, which is a JSON object representing all of the column's parameters. Column specifications are discussed in detail in the following section. Now let's overview the classes and functions.
Class or Function | Description |
|---|---|
The column type is the gateway between Structure and your code. The column type is registered with Structure and has the following responsibilities:
| |
The column is responsible for value rendering. It creates the HTML for the widget cells and controls the column's name and width. It can require one or more attributes to be downloaded from the server for the rendered rows. | |
The configurator is responsible for the column configuration panel as a whole. Its most important task is to create | |
The option is the workhorse of the configuration UI, corresponding to a single "row" of the configuration panel. It is responsible for creating the input elements and routing changes between them and the specification. | |
| Registers a column type with the Structure, making it responsible for handling the given column key (see below). |
| Registers a new group in the Add Column menu. |
6.2. Column Specifications
A column specification is a JSON object representing the complete configuration of a Structure widget column. Column specifications are stored as parts of view specifications. Each Column, ColumnConfigurator and ColumnOption instance has its own current specification, accessed via this.spec. A ColumnType is given a column specification when Structure wants it to create a Column or a ColumnConfigurator. ColumnType also creates column specifications for column presets. Finally, column specifications are passed to the export renderer providers on the server side (see below).
Do not confuse column specifications with attribute specifications. A column is a higher-level concept and may require multiple attributes (as is the case with our Status Bar column).
Here is an example of a Status Bar column specification.
{ "csid": "7",
"key": "com.almworks.jira.structure.sbcolumn",
"name": "Status Bar",
"params": {
"statuses": ["1", "3", "4", "5", "6", "10000"],
"colors": ["#fcaf3e", "#fce94f", "#ef2929", "#8ae234", "#ad7fa8", "#729fcf"],
"includeItself": true }}
Key | Description |
|---|---|
| The CSID ("column sequential ID") is a string that uniquely identifies a column within a view. CSIDs are assigned and managed by Structure, and should not bother you as a column developer. Do not change a column's CSID! |
| The key is a string identifying the column type. Structure uses the key to decide which |
| The column name is shown in the column header. The name is often omitted from the specification, in which case a default name is generated for the column. |
| This is a JSON object containing the column's parameters. The layout of this object is up to the column developer. In the example we see two parallel arrays for the selected status IDs and their colors, and a |
6.3. The Column Context
A column context is a JavaScript object providing various kinds of information about the environment, in which columns and their configurators operate. It is not to be confused with the somewhat similar in purpose, but unrelated AttributeContext on the server side. When Structure makes requests to the ColumnType, it passes the context as a parameter. Each Column, ColumnConfigurator or ColumnOption instance has its own current context, accessed via this.context. The table below describes the methods of the column context.
Method | Description |
|---|---|
| Returns |
| Returns |
| Returns |
| Returns |
| Returns |
| Returns |
| Returns |
| Returns |
| Returns |
| Returns an array of JSON objects representing available JIRA issue fields. |
| Returns a JSON object representing the JIRA issue field with the given ID, or |
| Returns the metadata object associated with the given |
In our column we'll use context.getMetadata().
6.4. Requesting and Using Metadata
Metadata, in the context of the column API, is any data needed by column types, columns, and configurators to to do their duties, except for attributes. For example, the Status Bar column needs to know the IDs and names of all the issue statuses in order to render tooltips and create presets – this is metadata. Structure provides some metadata by default – the getAllIssueFields() and getIssueFieldById() methods of the column context are examples, but you can load more via AJAX by issuing metadata requests.
Metadata is requested by overriding one or more of the methods in ColumnType, Column, and ColumnConfigurator classes. Let's look at an example from the Status Bar column type:
sbcolumn.js
getMetadataRequests: function() {
return {
status: {
url: baseUrl + '/rest/api/2/status',
cacheable: true,
extract: function(response) {
var result = { order: [], names: {} };
if ($.isArray(response)) {
response.forEach(function(status) {
result.order.push(status.id);
result.names[status.id] = status.name;
});
}
return result;
}
}
};
}
The method is supposed to return a JavaScript object. Each key in that object will become a metadata key for obtaining the corresponding result from the column context. In this example, the status-related metadata object will be obtained by calling context.getMetadata('status').
The values in the returned object are request specifications. Let's look at the request properties:
- The
urlproperty is the URL to be requested. Here we call a JIRA REST API method that returns all available issue statuses. Don't forget the JIRA base URL! - The
cacheableproperty is an opt-in mechanism for response caching. If a metadata request is cacheable, and this URL has already been requested (e.g. by a different column type), the previous response will be used instead of making a new AJAX request. You should declare your requests cacheable whenever possible to conserve traffic and improve responsiveness. - The
extractproperty is the function that receives the response and produces the value stored in the metadata map. If omitted, the response is stored unchanged. In the example, we convert the resulting array of JSON objects into an array of status IDs and a map from status IDs to status names. - You can add any other properties supported by
jQuery.ajax()to the request specification. Remember, though, that the jQuery success and error handlers will not be called for cacheable requests if a cached response is used.
Different metadata may be required for different operations. Therefore, there are several methods in the API that you can override to request metadata:
- A column type may request metadata to be able to:
- create column presets –
ColumnType.getPresetMetadataRequests(); - create columns from specifications –
ColumnType.getColumnMetadataRequests(); - create configurators from specifications –
ColumnType.getConfigMetadataRequests(); - do all of the above –
ColumnType.getMetadataRequests(), the "catch-all" method.
- create column presets –
- A column may need metadata to render its values –
Column.getMetadataRequests(). - A configurator may need metadata to set up the UI –
ColumnConfigurator.getMetadataRequests().
Please note that the corresponding type-level metadata is also available to the columns and configurators created by the type. So, for example, there is no need to issue the same requests in both ColumnType.getColumnMetadataRequests() and Column.getMetadataRequests(), the former alone will suffice.
Structure will delay loading the metadata for as long as possible. For example:
- the metadata for a column will not be loaded unless there is a column in the widget that needs it;
- the metadata for creating column presets will not be loaded until the user clicks "Add Column" or "Edit Column" icons;
- and so on.
Structure guarantees that the metadata request will be completed by the time it calls your type, column, and configurator methods (obviously, except for the getMetadataRequests() methods themselves). If the requests succeed, the metadata will be available in the column context. If they fail, the corresponding metadata will be undefined, but the methods will still be called, and they should not fail in that case.
6.5. Column
The api.Column class is responsible for rendering the cells of the Structure grid. Please refer to the Column class reference for the list of methods that you can override. The StatusBarColumn class in sbcolumn.js overrides four methods.
getDefaultName() simply returns a localized string as the column name when the name is not present in the column specification. A more involved column could use its specification, context, or metadata to determine the default column name.
canShrinkWhenNoSpace() allows Structure to make the column narrower than its minimum width when the widget is very low on horizontal space. Because we do not override any other sizing-related methods, the column will be resizable, with the default and minimum width of 120 and 27 pixels, respectively. Autosizing will not be applied to it, because there is no variable-size content, so autosizing makes no sense.
collectRequiredAttributes() always requests the status bar aggregate data from StatusBarAttributeProvider. If the "Include itself" option is off, it additionally requests the status ID of the current issue, which is provided by Structure as {id:'status',format:'id'}. The main attributes are also available from require('structure/widget/attributes/Attributes') object.
getSortAttribute() is used to specify the attribute for sorting when the user clicks on the column header.
getCellViewHtml() returns the actual HTML for the cells. It obtains the serialized status bar map from the renderParameters, deserializes it, adjusts for the "Include itself" option, if necessary, distributes the full status bar width of 100% among the selected statuses according to their issue counts, and finally generates and returns the status bar HTML code as a string. Please refer to the source code for the implementation details.
Please note, that for simple columns, displaying textual information, we advise you to override getCellValueHtml() instead, and let Structure take care of the boilerplate HTML surrounding your value. However, since we want the Status Bar to look similar to Structure's Progress Bar, we need to override a higher-level method and mimic the Progress Bar HTML layout.
6.6. ColumnConfigurator
The api.ColumnConfigurator class is responsible for the column configuration UI. Because most of the work is delegated to ColumnOption instances (see below), the configurators themselves are usually quite simple. Let's look at StatusBarConfigurator in its entirety.
sbcolumn.js
var StatusBarConfigurator = api.subClass('StatusBarConfigurator', api.ColumnConfigurator, {
init: function() {
this.spec.key = COLUMN_KEY;
this.spec.params || (this.spec.params = {});
},
getColumnTypeName: function() {
return AJS.I18n.getText("sbcolumn.name");
},
getGroupKey: function() {
return GROUP_KEY;
},
getOptions: function() {
return [new StatusesOption({ configurator: this }), new IncludeItselfOption({ configurator: this })];
}
});
The constructor, init() simply sanitizes the current column specification.
getColumnTypeName() returns the human-readable name for the column type. This name is used in the "Type" drop-down of the column configuration panel. You can also override getDefaultColumnName() to generate column names if the type name cannot always be used as the default column name.
getGroupKey() returns the key of the group in the "Add Column" menu that will contain this preset. See the sections on ColumnType and column groups below.
getOptions() creates and returns an array of ColumnOption instances that create input controls for the column configuration panel and route events. Please note how the configurator instance is passed to each option's constructor – this is crucial. The order of the options in the resulting array is also important – the rows of the configuration panel will be created in that order.
Although the methods of StatusBarConfigurator always return the same values, this is not a requirement. The result of any of the methods can depend on the current column specification (this.spec) and metadata.
6.7. ColumnOption
Each api.ColumnOption instance is responsible for editing a single logical "part" of the column specification, and corresponds to a single "row" of the column configuration panel. The option creates the actual input elements and sets up event handlers to transfer the values between the inputs and its column specification. An option can hide itself if it's not applicable to the current specification. Also, each option can prohibit saving the column configuration if it considers the current specification invalid – see isInputValid() method in the class reference.
Status Bar column has two options:
StatusesOptionis responsible for status selection, colors, and ordering. It "owns" thestatusesandcolorsarrays of a Status Bar column specification. This option is somewhat more involved than the next one, but you can still refer to its source code insbcolumn.js.IncludeItselfOptionis responsible for the "Include itself" checkbox and "owns" theincludeItselfspecification parameter. This is one of the simplest options imaginable, so we'll look at its code in detail.
sbcolumn.js
var IncludeItselfOption = api.subClass('IncludeItselfOption', api.ColumnOption, {
createInput: function(div$) {
this.checkbox$ = div$.append(
AJS.template('<div class="checkbox"><label><input type="checkbox"> {label}</label></div>')
.fill({ label: AJS.I18n.getText("sbcolumn.include-itself") })
.toString()).find('input');
var params = this.spec.params;
this.checkbox$.on('change', function() {
if ($(this).is(':checked')) {
params.includeItself = true;
} else {
delete params.includeItself;
}
div$.trigger('notify');
});
},
notify: function() {
this.checkbox$.prop('checked', !!this.spec.params.includeItself);
return true;
}
});
Because the option class specifies no title and doesn't override createLabel(), there is no label to the left of the checkbox.
The createInput() method creates the checkbox and sets up event handling. It is passed a jQuery object to append the input elements to.
Please note that Structure column configuration panels use the AUI Forms HTML layout (with modified CSS styles). You should use the same layout in your HTML code to make your options look consistent with Structure's. In the example above, the checkbox is wrapped in a <div class="checkbox"> element to comply with AUI Forms.
Also note how the change event handler of the checkbox modifies the current specification parameters and always triggers a notify event on the provided jQuery object. These are the crucial parts of the option contract.
The notify() method is called whenever the current specification changes. Its job is to transfer the data in the opposite direction – from the specification to the input elements. This method also decides whether the option is applicable – if it returns a "falsy" value, the option's row on the configuration panel is hidden from the user.
6.8. ColumnType
The api.ColumnType class is the main entry point used by the Structure plugin to call your client-side column code. A column type instance creates column presets, columns, and configurators. To find the complete source code for the Status Bar column type, please open sbcolumn.js from the API example sources in your favorite editor and scroll to the StatusBarType class definition.
The getMetadataRequests() method declares the column-level metadata request to load the available issue statuses from JIRA. See Requesting and Using Metadata above for details.
The createSwitchTypePreset() method creates a single column specification, which is used as a preset when the user selects our type in the "Type" drop-down on the column configuration panel.
Note the call to the isAvailable() function that checks that the preset is needed for the primary panel and that the status metadata is indeed available. If that check fails, the method returns null, making it impossible to switch to the Status Bar column type. You can try it yourself – open the Search Result secondary panel, add any column to it and try to change its column type. You should see that the Status Bar type is not available.
The switching preset doesn't have to be fully configured, because the configuration panel is already open when it's used. However, because the Status Bar column configuration is quite complex, we make an extra effort and pre-populate the preset with all the known statuses and some default colors for them. This way the user will quickly see what a status bar looks like without having to configure anything at all. This tactic can be useful for other columns with a lot of parameters.
The createAddColumnPresets() method creates an array of column specifications that will be used as presets in the "Add Column" menu. Unlike the "switch" preset above, these presets must be completely configured. Like createSwitchTypePreset(), this method calls isAvailable() first, so a Status Bar column cannot be added to a secondary Structure panel.
Because the "Add Column" menu is the first place where the user discovers your column type, it would be best if your presets are interesting and cover the whole range of the type's functionality. It's not easy to be creative with the Status Bar column though, unless we know the semantics of statuses, which can be arbitrary. So, for simplicity StatusBarType adds only a single preset to the "Add Column" menu, reusing the "switch" preset, which is fully configured.
Besides the usual key, name, and params, the "add" presets can have two special properties:
presetNameis a string that specifies the name of the preset in the "Add Column" menu. This name will be used only in the menu, the added column will have either thenamefrom the specification or the default name generated for it. If omitted, the column name will be used as the preset name.shouldOpenConfigurator– if this flag is set totrue, the column configuration panel will open immediately after adding the column with this preset. This can be used to create a "Custom..." kind of preset that lets the user explore the available options.
The createColumn() and createConfigurator() methods return a Column or a ColumnConfigurator for the given specification, respectively. The methods are similar – they check whether the type is available and the given specification is valid, and if both checks succeed, they instantiate the appropriate subclass. Please note how the column context and the specification are passed to the constructors, this is crucial.
Finally, at the end of the script we instantiate and register our column type, making it available to Structure:
sbcolumn.js
api.registerColumnType(new StatusBarType(), COLUMN_KEY);
Structure will use our column type instance to handle the columns with the given key. You can also pass an array of keys as the second argument, to associate your type with more than one column key.
6.9. Column Groups
Column groups are used to organize column presets in the "Add Column" menu. Each group has a string key and a human-readable name. Column configurator's getGroupKey() method should return the appropriate group key for its preset specification.
Structure specifies four column groups for its built-in columns – fields, icons, totals, and progress. For the Status Bar column we will register a separate column group:
sbcolumn.js
api.registerColumnGroup({ groupKey: GROUP_KEY, title: AJS.I18n.getText("sbcolumn.name"), order: 1000 });
The order parameter determines the position of the group within the menu. The higher the order, the lower the group will be. Structure's predefined groups have order between 100 and 400, inclusive.
6.10. Web Resources and Contexts
You need to register your JavaScript and CSS code as a web resource in the plugin descriptor. The Status Bar column has no CSS of its own, and all of its JavaScript code is in a single file, sbcolumn.js. Because we use the Structure JavaScript API and the AJS.template() function from the Atlassian API, we need to declare two dependencies. We also declare a resource transformation to make AJS.I18n.getText() calls work.
atlassian-plugin.xml
<web-resource key="wr-sbcolumn" name="web-resource:Status Bar Column">
<dependency>com.atlassian.auiplugin:ajs</dependency>
<dependency>com.almworks.jira.structure:widget</dependency>
<transformation extension="js">
<transformer key="jsI18n"/>
</transformation>
<resource type="download" name="sbcolumn.js" location="js/sbcolumn/sbcolumn.js"/>
<context>structure.widget</context>
</web-resource>
We use structure.widget web resource context to make our JavaScript (and CSS, if we had any) load on Structure Board. It also works for the Structure's Dashboard Gadget. However, if you'd like your column to work on other pages – Project page, Issue page or Agile Board page, you need to include other web contexts too – see Loading Additional Web Resources For Structure Widget.
7. Export Renderers
Any structure can be exported into printable HTML and Microsoft Excel formats. Exporting is different from rendering the Structure widget in several aspects:
- It is entirely a server-side task, so the code is written in Java.
- The data needed for exporting need not be transferred over the network and cached.
- The export result need not be updated as the exported issues or structure change.
- There are two distinct formats, or media, that are quite different from each other. More formats may be added in the future.
It is because of these differences, that the exporting architecture and APIs are different from their widget rendering counterparts, being simpler in some aspects and more complex in others, while quite similar overall, sometimes making it non-trivial to avoid "repeating yourself".
Please refer to the javadocs for an overview of the export API and SPI. In short, to export a column, you need to write and register an export renderer provider, that would recognize the column specification and return an export renderer instance for the given column and export format. The returned renderer will then be given an export column instance to configure and export cell instances to render the values. The export context and export row instances will provide all the data, including the required attributes.
Speaking of the interfaces that must be implemented, ExportRendererProvider is analogous to AttributeLoaderProvider, and ExportRenderer is a mixture of AttributeLoader and the client-side Column.
7.1. Export Strategies
The main difficulty with export is having different output formats with different features. For example, if you have a method for converting a value to HTML, you could reuse it for the printable HTML export. But when exporting to Excel, HTML support is very limited, and if your values correspond to one of Excel's data types, e.g. date, you need to set an appropriate column style. On the other hand, if you have a simple plain-text column, the format doesn't matter – you can have a single export renderer that calls setText() on any type of cell.
The export SPI is flexible, and allows you to use different strategies for different column types. There are three basic kinds of export renderer providers.
- A specific renderer provider declares which particular export format it supports in the plugin descriptor. It is parameterized with the expected column and cell types, and returns similarly parameterized renderers, that use format-specific methods.
- A generic renderer provider does not declare an export format in the plugin descriptor, so its priority is lower than that of a specific renderer provider. It returns generic renderers, that only call the methods of the basic
ExportCellandExportColumninterfaces. Though limited, such a provider will work for any other export format that may be added in the future. - A multi-format renderer provider either declares no supported formats (like a generic provider), or declares multiple supported formats. It is not parameterized with specific cell and column types, but it keeps track of the current export format, and its renderers may call format-specific methods by casting the given column and cell instances to the appropriate types. Though more difficult to write, a multi-format provider can combine the benefits of generic and specific providers and help avoid code duplication.
Exploring the extremes, we will create two export renderer providers for the Status Bar column. The first will be a generic provider, that will present the data as plain text instead of drawing a progress bar. The second one will be an advanced Excel provider that will use the underlying low-level Apache POI API to draw pseudo-graphic progress bars in Excel cells.
7.2. Generic Renderer Provider
The StatusBarRendererProvider class in the status-bar-column example plugin source contains both the generic provider and its renderer. The code is quite long, but that's mostly due to defensive checks and the general verbosity of Java. The operation of both the provider and the renderer is quite straight-forward.
The provider's getColumnRenderer() method does the following:
- Checks that the given column specification indeed represents a Status Bar column, just in case.
- Obtains the column name form the specification, generating a default name if there is none.
- Extracts the
statusesarray and theincludeItselfflag from the specification parameters. These are needed for rendering. - Creates and returns an instance of the
StatusBarRendererinner class, passing it the column name and parameters.
The renderer has prepare() method that lets it specify which attributes it will need loaded to do the export. Like in StatusBarColumn, we request our histogram-based custom attribute and status for the current row.
The renderer's configureColumn() method sets the column name by calling setText() on the given column's header cell.
The renderer's renderCell() method does the following:
- Obtains the attribute values from the context.
- Adjusts the data if the the "Include itself" option is off, by decrementing the issue count for the current issue's status.
- Iterates over the selected statuses, adding each non-zero sub-issue count and the corresponding status name to a
StringBuilder. - If the resulting value is not empty, calls
setText()on the given cell.
Here is the module declaration for the generic renderer provider. Note that it specifies the column key, but no export format.
atlassian-plugin.xml
<structure-export-renderer-provider key="erp-sbcolumn" name="export-renderer:Status Bar Column Provider"
class="com.almworks.jira.structure.sbcolumn.StatusBarRendererProvider">
<column-key>com.almworks.jira.structure.sbcolumn</column-key>
</structure-export-renderer-provider>
7.3. Advanced Excel Renderer Provider
The StatusBarExcelProvider class contains the advanced Excel renderer and the corresponding provider.
The provider's getColumnRenderer() method is very similar to the generic provider's, with two additions:
- it checks that the export format is indeed
MS_EXCEL; - it also extracts the
colorsarray from the specification parameters, as the renderer will use those (or similar) colors for the progress bar.
The renderer's prepare() and configureColumn() methods are the same as the generic version. The renderCell() method begins in a similar way, by extracting the data map and adjusting it for the "Include itself" option, if needed.
The interesting part is the actual rendering. The pseudo-graphic "progress bar" that the renderer creates is a string of 30 "pipe" characters, split into colored stripes with lengths proportional to issue counts. ExcelCell provides no support for rich text formatting (besides setRichTextFromHtml(), which is not up to the task), but we can access the lower-level API, Apache POI HSSF, by obtaining the underlying POI objects from ColumnContext.getObject() using the keys from ColumnContextKeys.Excel.
The code that distributes the 30 characters among the stripes is ported from sbcolumn.js. To completely understand how the rich text part works, you'll need some knowledge of the POI HSSF API, which is quite complex and outside of the scope of this document. Please refer to the POI documentation and the StatusBarExcelProvider source code for more information.
The module declaration for the Excel renderer provider is given below. Note that it specifies both a column key and an export format, thus overriding the generic provider for the Excel format.
atlassian-plugin.xml
<structure-export-renderer-provider key="erp-sbcolumn-excel" name="export-renderer:Status Bar Column Excel Provider"
class="com.almworks.jira.structure.sbcolumn.StatusBarExcelProvider">
<column-key>com.almworks.jira.structure.sbcolumn</column-key>
<export-format>ms-excel</export-format>
</structure-export-renderer-provider>