Structure 5.6 Release Notes
19th of September, 2019
Structure 5.6 adds column pinning, cache clearing, and more.Download the latest version of Structure and its Extensions
Try It: Structure Sandbox Server (no installation required)
1. Version Highlights
- Columns can be "pinned" to remain visible when horizontal scrolling is enabled.
- Structure caches can now be cleared for users and nodes from within the app.
- Adds support for Jira 8.4
2. Changes in Detail
2.1. Column Pinning
When Horizontal scrolling is enabled, the Summary column is "pinned" so that it will always be visible as users scroll through other columns. Now users can pin additional columns, so they will remain visible as well.
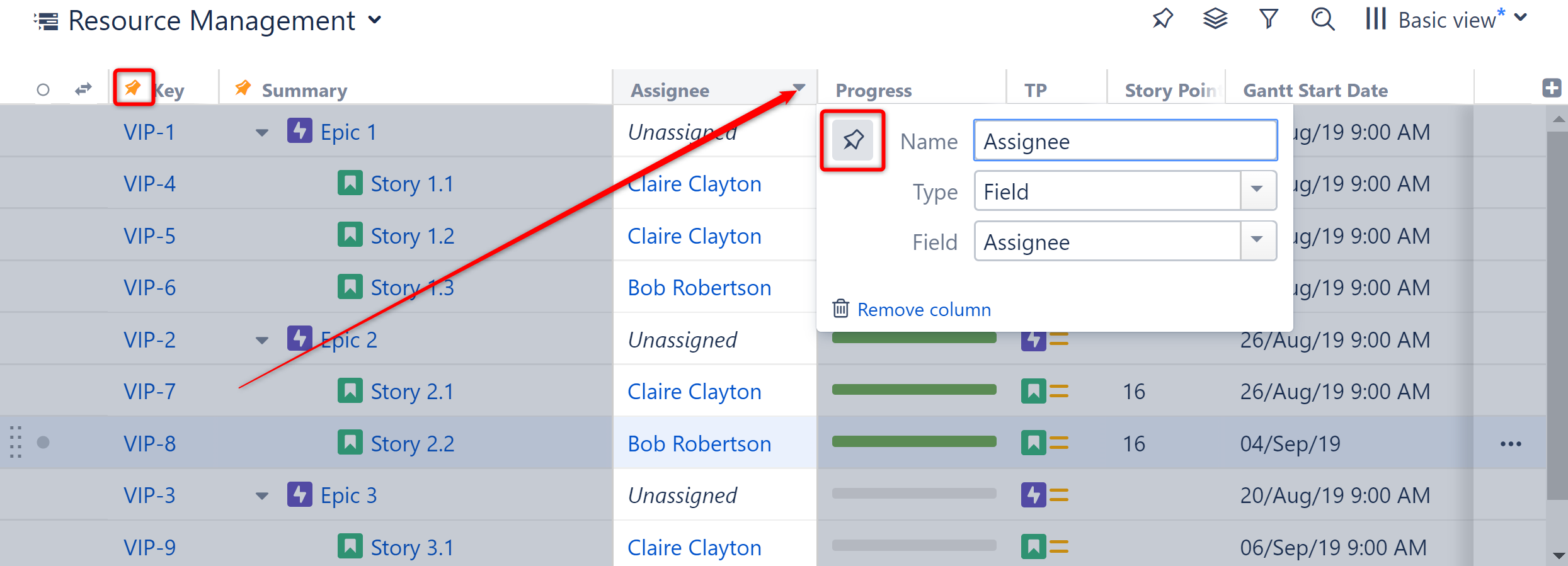
Pinned columns will be moved to the left side of the screen and will remain visible as you scroll.
Documentation: Horizontal Scrolling
2.2. Clearing Structure Caches
Structure caches can now be cleared from within the app for specific users or the whole Jira instance. In Jira Data Center, it's possible to clear caches for the current node or all nodes in the cluster.
![]()
Documentation: Clearing Structure Caches
2.3. Additional Updates
- Archived structures are now clearly marked as archived when opened.
- When viewing a structure on a Project page, the current project is auto-selected when adding a new issue.
- Fixed: Compatibility with Jira add-ons, "Links Hierarchy - Core, Epic & Portfolio" and "Tree CustomField"
3. Supported Versions
Structure 5.6 and all extensions support Jira versions 7.6 or later. All editions of Jira (Jira Core, Jira Software, Jira Service Desk) are supported. Jira Data Center is supported.
With respect to other add-ons and custom integrations, this release is backwards-compatible with Structure 3.4–5.5. Structure.Testy extension, Colors, Structure.Pages, Structure.Gantt and integrations with third-party apps should continue working normally.
4. Installation and Upgrade
Pick a Time
We strongly recommend that you install and upgrade your apps during off-peak hours or scheduled maintenance windows. There are known issues in the Jira plugin infrastructure that may cause performance degradation and impede app installation when your Jira instance is under heavy load.4.1. Installing Structure
If your Jira server does not have Structure yet, the installation is simple:
- Download and install Structure app, either from the Atlassian Marketplace or our Download page.
- When Add-on Manager reports the successful installation, click Get Started to visit a page with important guidance for the Jira administrator. You may want to also check out the user's Get Started page, available under the "Structure" top-level menu.
- Monitor
catalina.outorjira-application.logfor log messages from Structure.
4.2. Upgrading Structure
If you're upgrading from version 2.11.2 or earlier, please read Structure 3.0.0 Release Notes.
The upgrade procedure from versions 3.x–5.5 is simple:
- Consider backing up Jira data. Use Administration | System | Backup System. (If you have a large instance and a proper backup strategy in place, you may skip this step.)
- Back up Structure data. Use Administration | Structure | Backup Structure menu item. If you have a lot of structures and a large Jira, consider turning off the "Backup History" option to avoid a long backup process.
Install the new version of the plugin.
- Monitor
catalina.outorjira-application.logfor warnings or errors.
5. Enterprise Deployment Notes
Structure 5.6 contains a workaround for a performance problem that could affect extremely large Jira 7 instances, and a few other changes in important areas such as client-server communication, structure generation and locking, and user action handling.
5.1. Lucene Searcher Flushing
Jira uses Apache Lucene as the search engine behind JQL, and so Structure also relies on Lucene for JQL and a variety of other tasks, such as checking users' access to issues and reading issue data quickly. To work with Lucene, an app uses a Lucene searcher object provided by Jira. Lucene searchers are shared between Jira itself and all apps; when an issue is updated and re-indexed, the current Lucene searcher is released, and it can be garbage-collected when all tasks still using it are finished.
In Jira 7, on extremely large instances, Lucene searchers and associated data structures can consume huge amounts of memory – see JRASERVER-67805, JRASERVER-68439. This shouldn't affect Jira 8, which uses a newer version of Lucene, where these problems are fixed.
We have seen a few support cases, with very large Jira 7 instances, where a long-running Structure task would hold on to a Lucene searcher that consumes several gigabytes of memory. This would prevent the JVM from garbage-collecting the searcher and reclaiming that memory, which in turn would negatively affect the performance of the whole instance or cluster node. Note that Structure itself does not necessarily need all that memory; the shared searcher might get inflated by an unrelated task and then be given to Structure.
Lucene searcher flushing is a new, experimental dark feature introduced to work around this problem. If it's enabled, Structure will release ("flush") the Lucene searcher not at the end of a task, but immediately after using it. The JVM will then have a chance to garbage-collect the searcher without waiting for the current Structure task to finish.
Lucene searcher flushing is available only on Jira 7. It is enabled automatically for instances where the number of issues in the index multiplied by the number of searchable fields is greater than or equal to 230 (1,073,741,824). It can also be enabled or disabled manually by setting the structure.lucene.flushSearchers dark feature to "true" or "false", respectively. If you are running Jira 7, and your instance is above the threshold or close to it, and you have large structures that take a long time to generate, we advise that you load- and stress-test your instance before upgrading.
5.2. Reduced HTTP Thread Pool Usage
Structure does not perform potentially costly operations like structure generation in HTTP threads, offloading them to background thread pools instead. In previous versions of Structure, an HTTP thread would start a background job, wait for it to finish, and if it's not done in 10 seconds, return the job ID to the client. However, the client would immediately re-submit the request, and thus it would effectively always keep one HTTP thread busy for the duration of the background task.
As we have observed in a recent support case, on an overloaded Jira instance, Structure's background tasks could also slow down, and, in extreme cases, too many HTTP threads would be busy waiting for Structure tasks, making it hard for the instance to serve other HTTP requests.
To reduce chances of HTTP thread pool starvation, Structure 5.6 introduces client-side HTTP timeouts. When the client receives a job ID, it will wait 1 second before re-submitting the request, then 2 seconds, 4 seconds, and so on, up to 1 minute. We have also reduced the server-side timeout from 10 seconds to 5 seconds, so HTTP threads are returned to the pool sooner, improving the throughput.
5.3. Clearing Caches and Hard Refresh
In previous versions, hard-refreshing a page in the browser would cause Structure to clear its caches for the current user. We have decided to change this for two reasons. First, clearing the caches too often could negatively affect performance. Second, some of Structure's important caches are global, not per-user, and there was no easy way to clear them. Structure 5.6 introduces a new way of clearing caches. Hard-refreshing the page no longer works, so if you relied on it for troubleshooting Structure issues, please switch to the new interface.
5.4. Testing on Staging Environment
We advise you to perform load and stress testing in a staging environment before you upgrade. Given the changes in this version, you can try the following scenarios:
- Find or create a large automated structure that takes significant time to generate (around 30 seconds or more). Emulate multiple users opening it at the same time.
- Emulate multiple users making changes to Jira issues in this structure at a significant rate (say, one update every 1 or 2 seconds). Check that the structure re-generates to reflect the changes.
- Open a large manually-created structure containing 10,000 issues or more. Try moving one or more rows in this structure, note the time it takes to handle the moves.
While running these experiments, watch the log files for errors and warnings, and monitor heap usage and GC activity.